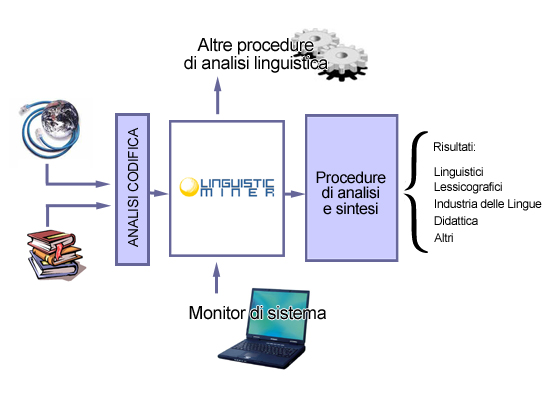
Il progetto “Linguistic miner” parte da una considerazione che sta alla base di tutti i sistemi di analisi linguistica “corpus based”: la miglior fonte di informazione linguistica, a qualunque livello di analisi la si consideri, è la lingua stessa rappresentata da un insieme di testi di grandi dimensioni delle più varie tipologie. Quanto più grandi sono i corpora disponibili e quanto più rappresentano in maniera eterogenea i vari ambiti linguistici (differenziati secondo diversi parametri quali il settore e le tipologie comunicative) tanto maggiore è la loro rappresentatività della realtà linguistica di una lingua.
Quindi primo elemento fondamentale è la capacità di costruire grandi corpora di riferimento della lingua; ma immediata necessità successiva è quella di poter creare e disporre di efficaci strumenti per la gestione di tali corpora, per la loro analisi e per la capacità di effettuare sintesi linguistica in maniera automatica.
Il progetto
“Linguistic
miner” nasce grazie alla capacità ed alla disponibilità
degli strumenti di trattamento e di analisi testuale del
progetto “PiSystem”
e da questo prende forza per aggregare nuove idee, nuove
metodologie,
nuovi strumenti, nuovi obiettivi e -crediamo- nuovi risultati.
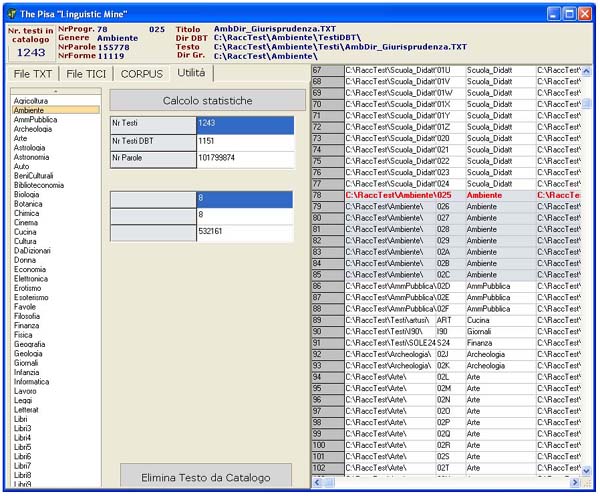
Il
cuore del progetto è costituito dal corpus di testi, in lingua
italiana che deve essere ricco e in continuo aggiornamento.
Per la propria
caratteristica di essere un corpus in continua crescita e per
la necessità
di avere necessità di materiali di facile accesso e di basso
costo di acquisizione il riferimento all’universo testuale
fornito
da Internet è ovvio e indiscutibile. Quindi, senza tralasciare
la possibilità di utilizzare materiale testuale da qualsiasi
fonte possa provenire la parte fondamentale del nuovo corpus
di riferimento
sarà acquisita in maniera automatica da Internet. Un primo
blocco
di procedure del sistema sarà costituito da moduli per lo
spidering
nel WEB con acquisizione automatica di materiale testuale.
Data la necessità
di controllare, di valutare e di categorizzare (ad un primo
livello
di classificazione) i testi, si è scelto di non utilizzare
degli
spider generici bensì di creare moduli di ricerca e di
scaricamento
che operano in modalità “guidata” dove è l’operatore
a selezionare siti, insiemi di pagine ed elementi di un sito
che siano
significativi ed importanti per il progetto stesso. Una
particolare
importanza rivestono i siti che potremmo definire rinnovabili,
quali
siti dei giornali, di “Web news”, di riviste e simili nei
quali è possibile automatizzare la fase di acquisizione a
scadenze
periodiche costituendo una formidabile fonte di testi per il
progetto.
Il problema del copyright. Chiaramente con tale approccio
abbiamo immediatamente
da scontrarci con il problema del copyright che copre
certamente la
stragrande maggioranza del materiale che possiamo in questo
modo acquisire.
La struttura implicita del sistema “Linguistic miner” che
è destinato a costituire un insieme di materiali testuali non
necessariamente articolati secondo le proprie strutture ma
finalizzati
alla analisi ed alla sintesi dei fenomeni linguistici
sottostanti permettono
di predisporre una fase di analisi del materiale già nella
prima
fase di acquisizione procedendo ad un’inserimento nella grande
base dati che costituisce la “miniera” del progetto in forma
già destrutturata, focalizzando i singoli elementi linguistici
che costituiscono la specifica ricchezza di quel testo per il
progetto
ma inibendo al tempo stesso la capacità di riprodurre il testo
in quanto tale, impedendone quindi una sua lettura, una sua
riproduzione.
Tale operatività da una parte rende il materiale non più
strettamente dipendente dalla sorgente originale e, al tempo
stesso,
nulla toglie alle potenzialità ed agli obiettivi del progetto
che rimangono puramente linguistici e non di analisi dei
contenuti e
di ricerca documentale.
Procedure di inserimento nella banca dati “Mine”. Le procedure
di acquisizione, basate principalmente sul Web, hanno il
compito di
individuare e scaricare pagine testo in formato HTML; tale
formato è
caratterizzato dall’avere una serie di connotatori (tag)
finalizzati
diremmo esclusivamente alla composizione grafica della pagina
nel vari
browser disponibili e non contengono esplicite indicazioni per
identificare
il ruolo di ogni specifico elemento che appare nella pagina
(immagini,
testo, agganci a nuovi siti, rimandi ipertestuali, funzioni,
espresse
in numerosi sistemi di codifica e di programmazione, per la
visualizzazione
di vari elementi. La necessità di identificare in tali pagine
la parte testuale e di classificarla il più correttamente
possibile
per i successivi programmi di analisi ha portato alla
realizzazione
di tutta una serie di procedure per l’interpretazione e la
corretta
codifica dei materiali individuati. Tale tipologia di
strumento di codifica
è stato realizzato, con diverse percentuali di rendimento,
anche
per altre tipologie di materiale che si sia reso disponibile
(Word,
RTF (Rich Text Format), testi in formato PDF della Adobe).
Procedure di pre-editing dei materiali per un miglior
risultato delle
procedure di analisi. Chiaramente la qualità dei risultati che
potranno essere ottenute da procedure di analisi linguistica
automatica
dipendono dalla quantità di elementi del testo che possono
essere
correttamente etichettate e questo è molto importante poter
predisporre
tutta una serie di funzioni di classificazioni del materiale
testuale.
All’interno del progetto “Linguistic miner” e del precedente
progetto “PiSystem” sono state sviluppate procedure per
l’individuazione
ed il trattamento di fenomeni quali: struttura del testo,
sigle, abbreviazioni
(per differenziare l’uso del punto nel caso di abbreviazione),
nomi propri (singole parole o espressioni), link a siti
internet, link
ipertestuali in genere, indirizzi di posta elettronica.
Il sistema è pensato per poter gestire una quantità di
testo di dimensioni praticamente illimitata e si prevede di
giungere
già in un breve tempo di applicazione ad una “miniera”
di alcune centinaia di milioni di parole.
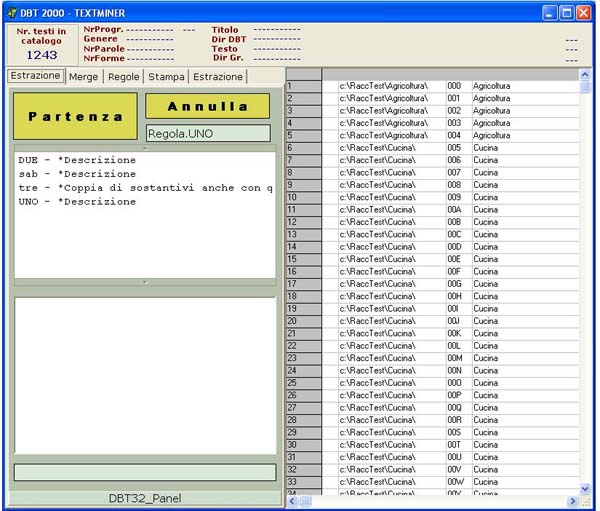
La
centrale di controllo. Il sistema “Linguistic Miner” è
completamente integrato in un insieme di dati, risorse,
strumenti che
permette di svolgere tutte le funzioni di gestione ed
elaborazione proprie
del sistema stesso. La gestione del sistema avviene da una
codetta “console”
che mostra lo stato della “miniera” di testi, ne permette
la gestione e la classificazione ad un primo livello e
permette l’avvio
di procedure di analisi successive.
La fase di classificazione di primo livello permette la
categorizzazione
di ogni testo immesso, l’informazione necessaria a tale
operazione
sarà rilevata dalla provenienza del materiale e da una sua
analisi
di primo impatto; essa fornisce una primo indice di
classificazione
del materiale pere una utilizzazione ragionata e comparativa
di settore.
La fase di classificazione dei singoli elementi della
“miniera”
costituirà una delle fasi di sviluppo successive.
Fase di estrazione dalla “linguistic mine”. La fase di
sfruttamento
dei dati testuali che verranno stratificandosi all’interno
della
miniera costituisce il momento più importante ed eccitante di
tutto il progetto.
Chiaramente gli strumenti già disponibili, tramite l’ambiente
“PiSystem” e la sua procedura di base DBT (Data Base Testuale)
costituiscono il nucleo centrale ed iniziale dell’insieme di
strumenti
per l’estrazione e la sintesi di informazioni linguistiche
dalla
grande fonte di materiale testuale che il sistema riesce a
mettere insieme.
E’ altresì importante considerare come la fase di costruzione
di modelli e strumenti per tale compito specifico costituisce
già
di per sé un obiettivo fondamentale di tutta l’attività
del progetto.
Comunque già importanti risultati possono essere ottenuti con
gli strumenti attualmente disponibili: in particolari a fini
lessicografici
possono essere estratti le concordanze di singole parole, di
singoli
lemmi, di specifiche locuzioni o co-occorrenze presentate in
vari modi:
in ordine sinistro, in ordine destro, differenziando secondo
la tipologia
del testo.
Tutte le funzioni già disponibili di analisi e navigazione nel
testo possono essere utilizzate, ma interessante risulta anche
l’utilizzazione
di un nuovo programma che è in fase di perfezionamento. Il
programma
in oggetto ha il compito di permettere la definizione di
pattern linguistici
e la loro applicazione a tutta la “miniera” o ad un suo
sottoinsieme
opportunamente selezionato. Il programma permette quindi la
ricerca
di specifici modelli linguistici all’interno del corpus.